
GLM-TTS Technical Report
Paper • 2512.14291 • Published • 1
📜 Paper | 💻 GitHub Repository | 🛠️ Audio.Z.AI
GLM-TTS is a high-quality text-to-speech (TTS) synthesis system based on large language models, supporting zero-shot voice cloning and streaming inference. The system adopts a two-stage architecture combining an LLM for speech token generation and a Flow Matching model for waveform synthesis.
By introducing a Multi-Reward Reinforcement Learning framework, GLM-TTS significantly improves the expressiveness of generated speech, achieving more natural emotional control compared to traditional TTS systems.
GLM-TTS follows a two-stage design:
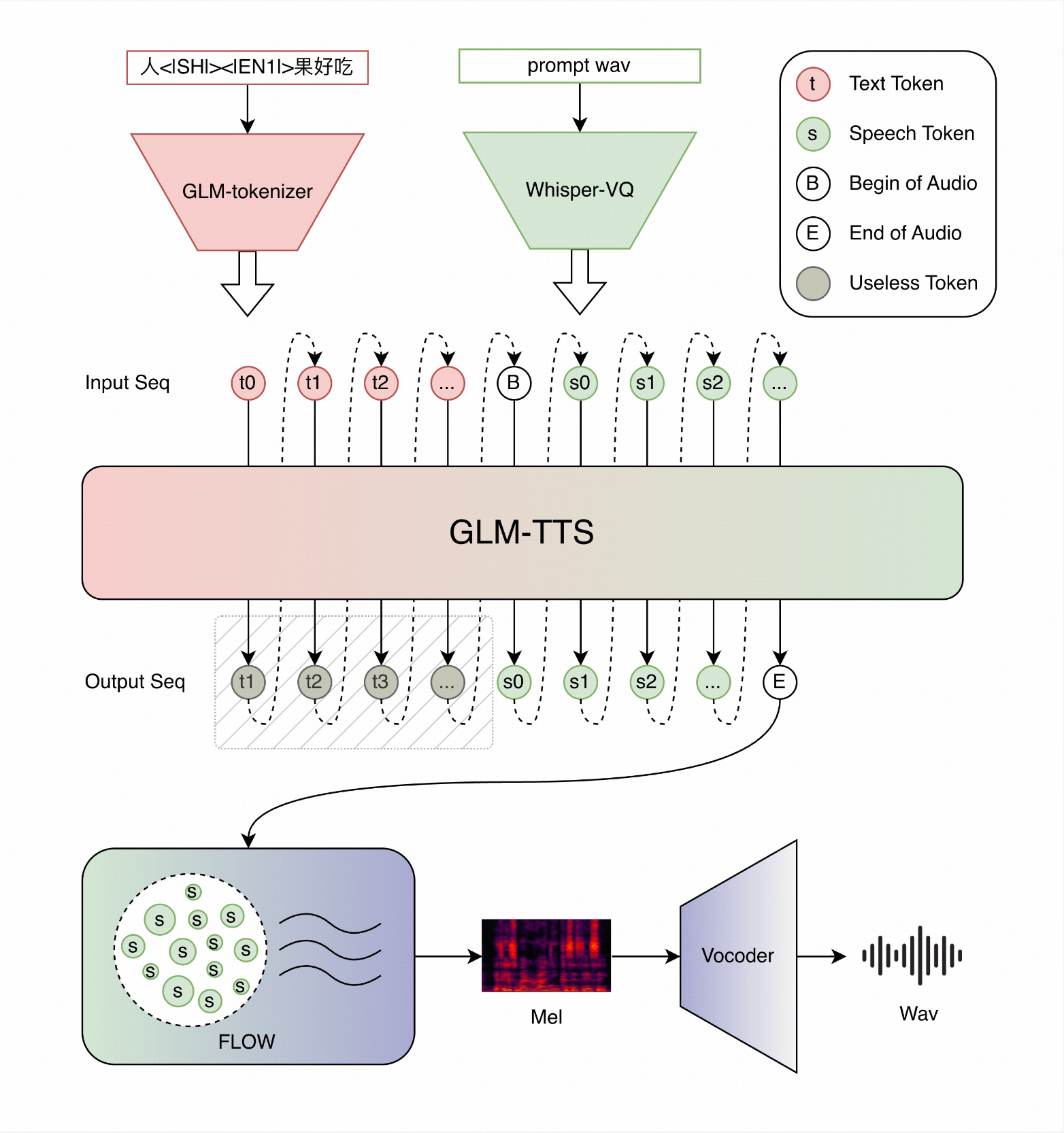
To tackle flat emotional expression, GLM-TTS uses a Group Relative Policy Optimization (GRPO) algorithm with multiple reward functions (Similarity, CER, Emotion, Laughter) to align the LLM's generation strategy.
Evaluated on seed-tts-eval. GLM-TTS_RL achieves the lowest Character Error Rate (CER) while maintaining high speaker similarity.
| Model | CER ↓ | SIM ↑ | Open-source |
|---|---|---|---|
| Seed-TTS | 1.12 | 79.6 | 🔒 No |
| CosyVoice2 | 1.38 | 75.7 | 👐 Yes |
| F5-TTS | 1.53 | 76.0 | 👐 Yes |
| GLM-TTS (Base) | 1.03 | 76.1 | 👐 Yes |
| GLM-TTS_RL (Ours) | 0.89 | 76.4 | 👐 Yes |
git clone [https://github.com/zai-org/GLM-TTS.git](https://github.com/zai-org/GLM-TTS.git)
cd GLM-TTS
pip install -r requirements.txt
python glmtts_inference.py \
--data=example_zh \
--exp_name=_test \
--use_cache \
# --phoneme # Add this flag to enable phoneme capabilities.
bash glmtts_inference.sh
We thank the following open-source projects for their support:
If you find GLM-TTS useful for your research, please cite our technical report:
@misc{cui2025glmttstechnicalreport,
title={GLM-TTS Technical Report},
author={Jiayan Cui and Zhihan Yang and Naihan Li and Jiankun Tian and Xingyu Ma and Yi Zhang and Guangyu Chen and Runxuan Yang and Yuqing Cheng and Yizhi Zhou and Guochen Yu and Xiaotao Gu and Jie Tang},
year={2025},
eprint={2512.14291},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2512.14291},
}
}