
DFlash
Collection
Block Diffusion for Flash Speculative Decoding • 21 items • Updated • 110
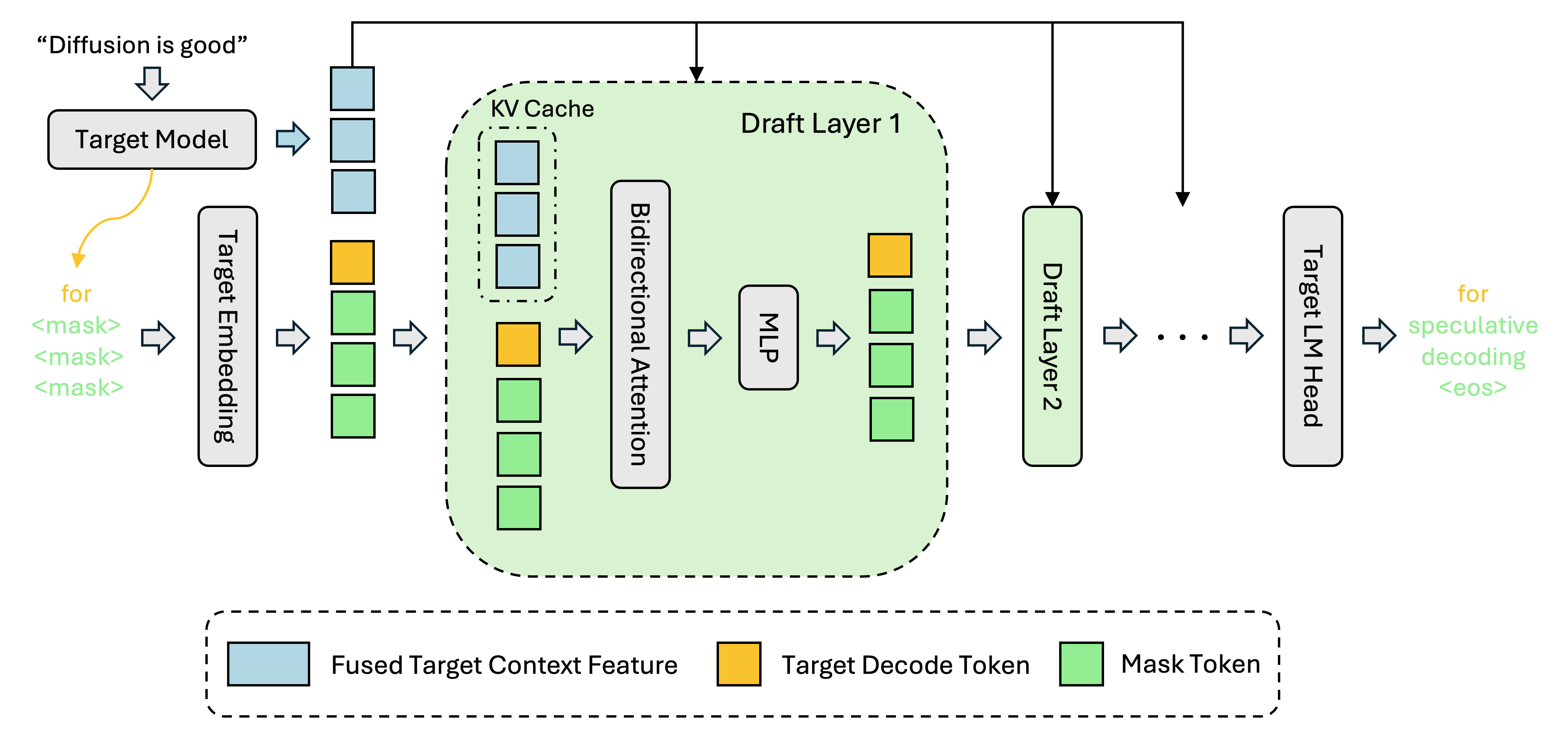
DFlash is a speculative decoding method that uses a lightweight block diffusion model to draft multiple tokens in parallel. This is the drafter model, which must be paired with google/gemma-4-26B-A4B-it.
vLLM: until Gemma4 DFlash support is merged, install vLLM from PR #41703:
uv pip install -U --torch-backend=auto \
"vllm @ git+https://github.com/vllm-project/vllm.git@refs/pull/41703/head"
SGLang:
uv pip install "git+https://github.com/sgl-project/sglang.git@refs/pull/23000/head#subdirectory=python"
vLLM:
vllm serve google/gemma-4-26B-A4B-it \
--speculative-config '{"method": "dflash", "model": "z-lab/gemma-4-26B-A4B-it-DFlash", "num_speculative_tokens": 15, "attention_backend": "flash_attn"}' \
--attention-backend triton_attn \
--max-num-batched-tokens 32768 \
--trust-remote-code
SGLang:
# Optional: enable schedule overlapping (experimental, may not be stable)
# export SGLANG_ENABLE_SPEC_V2=1
# export SGLANG_ENABLE_DFLASH_SPEC_V2=1
# export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path google/gemma-4-26B-A4B-it \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/gemma-4-26B-A4B-it-DFlash \
--speculative-num-draft-tokens 16 \
--tp-size 1 \
--attention-backend triton \
--speculative-draft-attention-backend fa4 \
--trust-remote-code
For vLLM, use port 8000. For SGLang, use port 30000.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="google/gemma-4-26B-A4B-it",
messages=[{"role": "user", "content": "Write a quicksort in Python."}],
max_tokens=4096,
temperature=0.0,
extra_body={"chat_template_kwargs": {"enable_thinking": True}},
)
print(response.choices[0].message.content)
Setup: Single NVIDIA B300 GPU per server/run, vLLM, thinking enabled, max output length 4096, greedy decoding.
DFlash achieves up to 3.7x speedup at concurrency 8.
Generated tokens/sec (speedup vs. autoregressive baseline)
Block Size = 16
| Task | Concurrency | AR | DFlash |
|---|---|---|---|
| Math500 | 1 | 259 | 925 (3.6x) |
| 8 | 1296 | 4837 (3.7x) | |
| 32 | 3233 | 11435 (3.5x) | |
| GSM8K | 1 | 256 | 825 (3.2x) |
| 8 | 1217 | 4241 (3.5x) | |
| 32 | 3174 | 10306 (3.2x) | |
| HumanEval | 1 | 246 | 818 (3.3x) |
| 8 | 1182 | 4240 (3.6x) | |
| 32 | 2881 | 9150 (3.2x) | |
| MBPP | 1 | 272 | 698 (2.6x) |
| 8 | 1288 | 3387 (2.6x) | |
| 32 | 2950 | 7898 (2.7x) | |
| MT-Bench | 1 | 272 | 492 (1.8x) |
| 8 | 1146 | 2259 (2.0x) | |
| 32 | 2164 | 4829 (2.2x) |
| Task | c1 | c8 | c32 |
|---|---|---|---|
| Math500 | 8.61 | 8.55 | 8.60 |
| GSM8K | 7.71 | 7.76 | 7.72 |
| HumanEval | 7.80 | 7.87 | 7.83 |
| MBPP | 6.09 | 5.99 | 6.03 |
| MT-Bench | 4.33 | 4.33 | 4.24 |
Special thanks to David Wang for his outstanding engineering support on this project. We are also grateful to Modal, InnoMatrix, and Yotta Labs for providing the compute resources used to train this draft model.
If you find DFlash useful, please cite our work. To share feedback on DFlash or request new model support, please fill out this form: DFlash Feedback.
@article{chen2026dflash,
title = {{DFlash: Block Diffusion for Flash Speculative Decoding}},
author = {Chen, Jian and Liang, Yesheng and Liu, Zhijian},
journal = {arXiv preprint arXiv:2602.06036},
year = {2026}
}
Install from pip and serve model
# Install vLLM from pip: pip install vllm# Start the vLLM server: vllm serve "z-lab/gemma-4-26B-A4B-it-DFlash"# Call the server using curl (OpenAI-compatible API): curl -X POST "http://localhost:8000/v1/completions" \ -H "Content-Type: application/json" \ --data '{ "model": "z-lab/gemma-4-26B-A4B-it-DFlash", "prompt": "Once upon a time,", "max_tokens": 512, "temperature": 0.5 }'