

library_name: transformers
tags:
- multimodal
- multilingual
- llm
- vision
- vlm
- translation
language:
- en
- de
- nl
- es
- fr
- pt
- uk
- hi
- zh
- ru
- cs
- ko
- ja
- it
- pl
- ro
- nb
- nn
base_model:
- Unbabel/Tower-Plus-2B
pipeline_tag: image-text-to-text
Model Card for TowerVision

TowerVision is a family of open-source multilingual vision-language models with strong capabilities optimized for a variety of vision-language use cases, including image captioning, visual understanding, summarization, question answering, and more. TowerVision excels particularly in multimodal multilingual translation benchmarks and culturally-aware tasks, demonstrating exceptional performance across 20 languages and dialects.
This model card covers the TowerVision family, including the 2B and 9B parameter versions, both in their instruct-tuned (it) and pretrained (pt) variants, with the latter not undergoing instruction tuning.
- Point of Contact: X (add some email here)
- License: Apache 2.0
- Model Family: TowerVision (2B, 9B variants)
- Context length: 8192 tokens
- Languages: 20+ languages including European, Asian, and other language families
🌟 Try TowerVision: Project Page | Code Repository
Available Models
| Model | Parameters | HF Link |
|---|---|---|
| TowerVision-2B | 2B | 🤗 utter-project/TowerVision-2B |
| TowerVision-2B-pt | 2B | 🤗 utter-project/TowerVision-2B-pt |
| TowerVision-9B | 9B | 🤗 utter-project/TowerVision-9B |
| TowerVision-9B-pt | 9B | 🤗 utter-project/TowerVision-9B-pt |
| TowerVideo-2B | 2B | 🤗 utter-project/TowerVision-2B |
| TowerVideo-9B | 9B | 🤗 utter-project/TowerVision-9B |
How to Use TowerVision
Quick Start with Transformers
Click to expand/collapse code
mport torch
from transformers import AutoProcessor, LlavaOnevisionForConditionalGeneration
# Load the model in half-precision
model = LlavaOnevisionForConditionalGeneration.from_pretrained(
"/mnt/data-poseidon/saul/towerpvideo_hf",
device_map="auto"
)
processor = AutoProcessor.from_pretrained(
"utter-project/TowerVideo-7B"
)
# Use your local video
video_path = "your_video_path.mp4"
# Conversation using the same template
conversation = [
{
"role": "user",
"content": [
{"type": "video", "path": video_path},
{"type": "text", "text": "\n<video>\nIWhat is the video about?"},
],
},
]
# Apply the chat template
inputs = processor.apply_chat_template(
conversation,
num_frames=8,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
add_special_tokens=True, # ensures <video> token is inserted
return_tensors="pt"
).to(model.device, torch.float16)
# Generate response
out = model.generate(**inputs, max_new_tokens=60)
# Decode output
decoded = processor.batch_decode(
out,
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)
print(decoded)
Model Details
Input: Model accepts input text, images and video.
Output: Model generates text in multiple languages.
Model Architecture: TowerVision uses a multilingual image-language model based on Tower-Plus (2B and 9B parameters), paired with SigLIP2-patch14-384 vision encoder through a multimodal adapter for vision-language understanding.
Recommended Precision: We recommend using bfloat16 precision for optimal performance and memory efficiency when running TowerVision models.
Languages Covered: The model has been trained on 20 languages and dialects:
- European languages: English, German, Dutch, Spanish, French, Portuguese, Italian, Polish, Czech, Romanian, Norwegian (Bokmål & Nynorsk)
- Asian languages: Chinese (Simplified & Traditional), Japanese, Korean, Hindi
- Other languages: Russian, Ukrainian
Key Strengths:
- 🏆 Exceptional performance on culturally-aware benchmarks with deep understanding of cultural contexts and visual nuances
- 📊 Strong cross-lingual transfer capabilities across diverse vision-language tasks
Training Data
TowerVision models are trained on VisionBlocks, a comprehensive multilingual vision-language dataset comprising 6.31M samples across diverse categories:
| Dataset | Samples | HF Link | |
|---|---|---|---|
| VisionBlocks | 6.31M | 🤗 utter-project/VisionBlocks | Coming Soon |
Dataset Statistics
- Total samples: 6.31M
- Created by our team: 1.21M samples (~19%)
- Human-collected/external: 5.10M samples (~81%)
Dataset Composition Overview
VisionBlocks contains samples across multiple categories with both English-only (63.1%) and multilingual (36.9%) data:
- Chart/Plot Reasoning: DVQA, ChartQA, PlotQA, TabMWP (~405K samples)
- General VQA: VQAv2, RLAIF-4V (~488K samples)
- Document VQA: DocVQA, TextVQA, ST-VQA, PixMo-Docs (~46K samples)
- Reasoning/Knowledge: A-OKVQA, OKVQA, AI2D, ScienceQA (~29K samples)
- Multilingual/Cultural: Pangea-Cultural, Pangea-Multi, PixMo-Cap-Translated, CulturalGround datasets (~1.6M samples)
- Specialized VQA: IconQA, InfographicVQA, Stratos (~34K samples)
- Counting/Math: TallyQA, PixMo-Count (~107K samples)
- Vision/Text: VBlocks-PixMo collections, EuroBlocks-SFT (~2.2M samples)
- Video/Text: LLaVA-Video collections (~1.4M samples)
Collection Types: Human-annotated, synthetically generated, and professionally translated data ensuring high quality and cultural diversity across 20+ languages.
Evaluation
All evaluations were conducted using lmms_eval.
Multiple Purpose Multimodal Benchmarks
TowerVision demonstrates strong performance across diverse multimodal evaluation benchmarks:
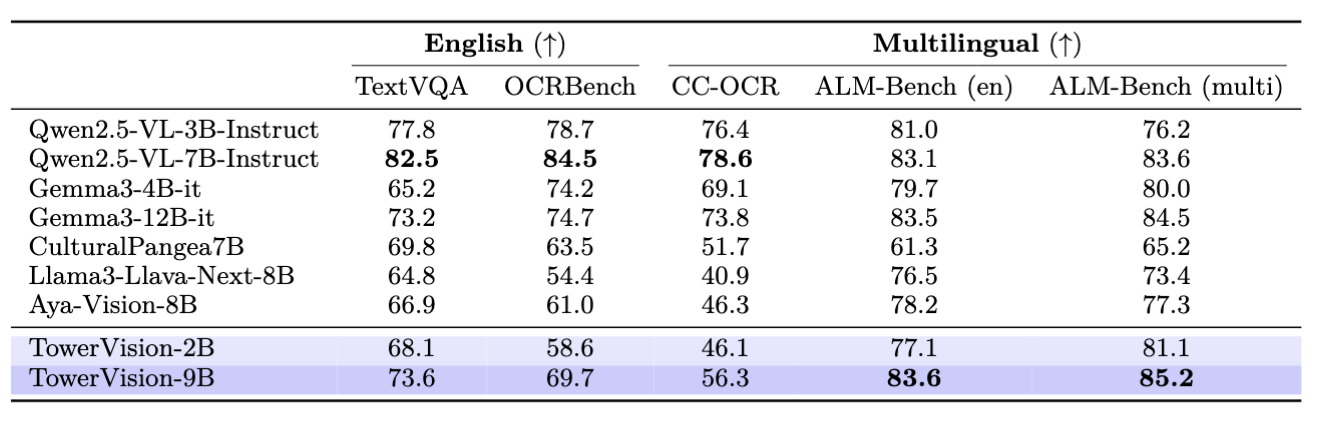
Multimodal Multilingual Translation Tasks
TowerVision excels particularly in multimodal multilingual translation benchmarks, demonstrating state-of-the-art cross-lingual visual communication capabilities:
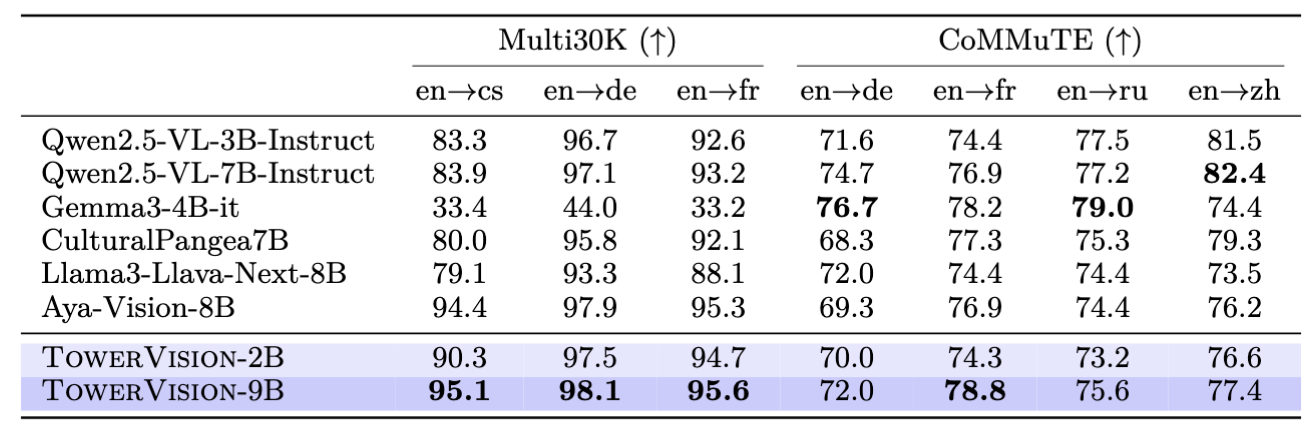
Supported Languages Performance
✅ Fully Supported: English, German, Dutch, Spanish, French, Portuguese, Italian, Polish, Czech, Romanian, Norwegian, Chinese, Japanese, Korean, Hindi, Russian, Ukrainian
📊 Benchmark Coverage: Our models are evaluated across diverse multilingual vision-language tasks, demonstrating strong cross-lingual transfer capabilities and exceptional performance in culturally-aware benchmarks.
Citation
If you find TowerVideo useful in your research, please consider citing the following paper:
@article{towervision2025,
title={Understanding and Improving Multilinguality in Vision-Language Models},
author={[Authors to be added]},
journal={[Journal to be added]},
year={2025},
note={Paper in preparation}
}
Model Card Contact
For errors or additional questions about details in this model card, contact the research team.
Terms of Use
We hope that the release of this model will make community-based research efforts more accessible by releasing the weights of highly performant multilingual vision-language models to researchers all over the world.
This model is governed by the Apache 2.0 License.
Acknowledgments
TowerVision builds upon the excellent work of:
- LLaVA-NeXT for the foundational vision-language architecture
- Tower-Plus language models for multilingual capabilities
- SigLIP2 for robust vision encoding
- The broader multilingual NLP and multimodal communities