---
language:
- zh
- en
tags:
- llm
- tts
- zero-shot
- voice-cloning
- reinforcement-learning
- flow-matching
license: mit
pipeline_tag: text-to-speech
---
# GLM-TTS: Controllable & Emotion-Expressive Zero-shot TTS
💻 GitHub Repository
|
🛠️ Audio.Z.AI
## 📖 Model Introduction
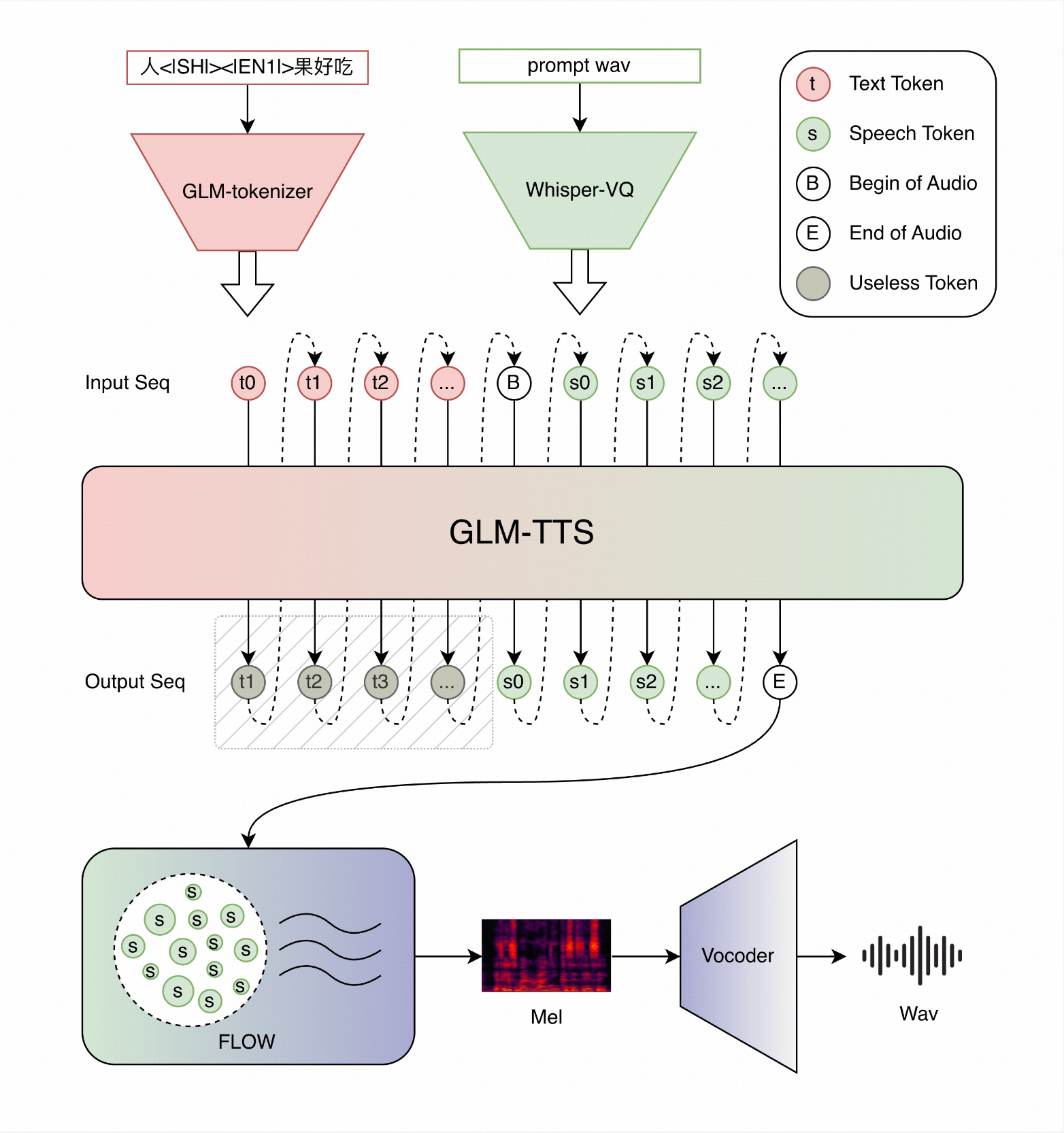
GLM-TTS is a high-quality text-to-speech (TTS) synthesis system based on large language models, supporting zero-shot voice cloning and streaming inference. The system adopts a two-stage architecture combining an LLM for speech token generation and a Flow Matching model for waveform synthesis.
By introducing a **Multi-Reward Reinforcement Learning** framework, GLM-TTS significantly improves the expressiveness of generated speech, achieving more natural emotional control compared to traditional TTS systems.
### Key Features
* **Zero-shot Voice Cloning:** Clone any speaker's voice with just 3-10 seconds of prompt audio.
* **RL-enhanced Emotion Control:** Utilizes a multi-reward reinforcement learning framework (GRPO) to optimize prosody and emotion.
* **High-quality Synthesis:** Generates speech comparable to commercial systems with reduced Character Error Rate (CER).
* **Phoneme-level Control:** Supports "Hybrid Phoneme + Text" input for precise pronunciation control (e.g., polyphones).
* **Streaming Inference:** Supports real-time audio generation suitable for interactive applications.
* **Bilingual Support:** Optimized for Chinese and English mixed text.
## System Architecture
GLM-TTS follows a two-stage design:
1. **Stage 1 (LLM):** A Llama-based model converts input text into speech token sequences.
2. **Stage 2 (Flow Matching):** A Flow model converts token sequences into high-quality mel-spectrograms, which are then turned into waveforms by a vocoder.
### Reinforcement Learning Alignment
To tackle flat emotional expression, GLM-TTS uses a **Group Relative Policy Optimization (GRPO)** algorithm with multiple reward functions (Similarity, CER, Emotion, Laughter) to align the LLM's generation strategy.
## Evaluation Results
Evaluated on `seed-tts-eval`. **GLM-TTS_RL** achieves the lowest Character Error Rate (CER) while maintaining high speaker similarity.
| Model | CER ↓ | SIM ↑ | Open-source |
| :--- | :---: | :---: | :---: |
| Seed-TTS | 1.12 | **79.6** | 🔒 No |
| CosyVoice2 | 1.38 | 75.7 | 👐 Yes |
| F5-TTS | 1.53 | 76.0 | 👐 Yes |
| **GLM-TTS (Base)** | 1.03 | 76.1 | 👐 Yes |
| **GLM-TTS_RL (Ours)** | **0.89** | 76.4 | 👐 Yes |
## Quick Start
### Installation
```bash
git clone [https://github.com/zai-org/GLM-TTS.git](https://github.com/zai-org/GLM-TTS.git)
cd GLM-TTS
pip install -r requirements.txt
```
#### Command Line Inference
```bash
python glmtts_inference.py \
--data=example_zh \
--exp_name=_test \
--use_cache \
# --phoneme # Add this flag to enable phoneme capabilities.
```
#### Shell Script Inference
```bash
bash glmtts_inference.sh
```
## Acknowledgments & Citation
We thank the following open-source projects for their support:
- [CosyVoice](https://github.com/FunAudioLLM/CosyVoice) - Providing frontend processing framework and high-quality vocoder
- [Llama](https://github.com/meta-llama/llama) - Providing basic language model architecture
- [Vocos](https://github.com/charactr-platform/vocos) - Providing high-quality vocoder
- [GRPO-Zero](https://github.com/policy-gradient/GRPO-Zero) - Reinforcement learning algorithm implementation inspiration
If you use GLM-TTS in your research, please cite:
```bibtex
@misc{glmtts2025,
title={GLM-TTS: Controllable & Emotion-Expressive Zero-shot TTS with Multi-Reward Reinforcement Learning},
author={CogAudio Group Members},
year={2025},
publisher={Zhipu AI Inc}
}