

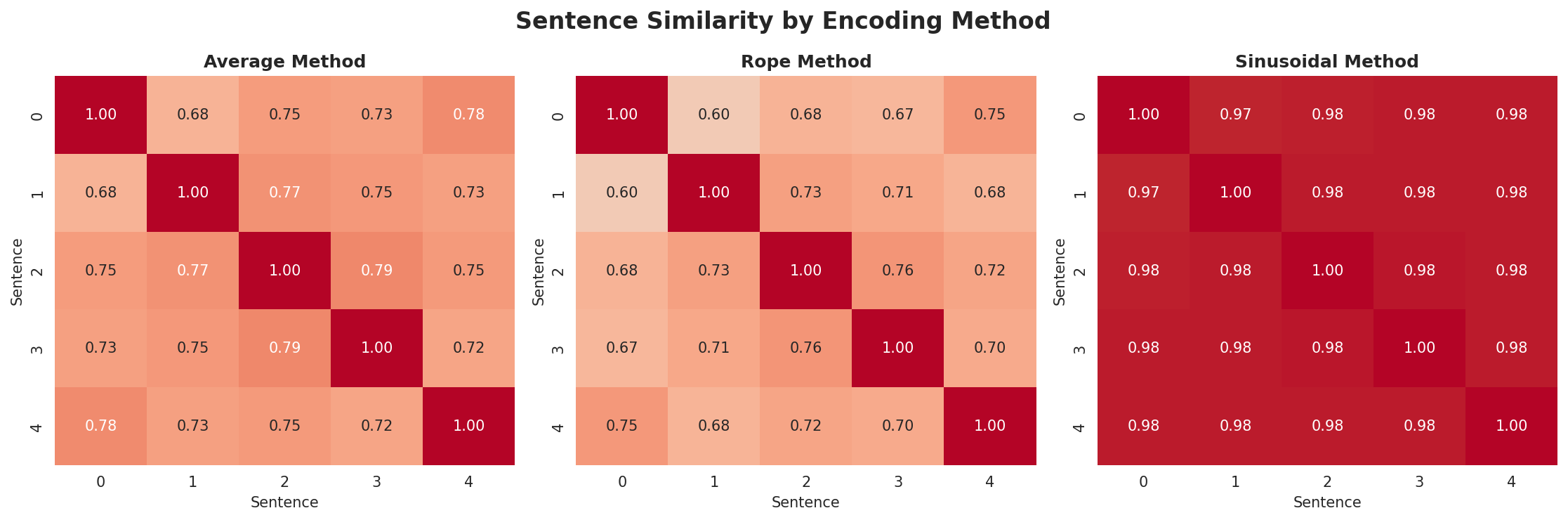
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
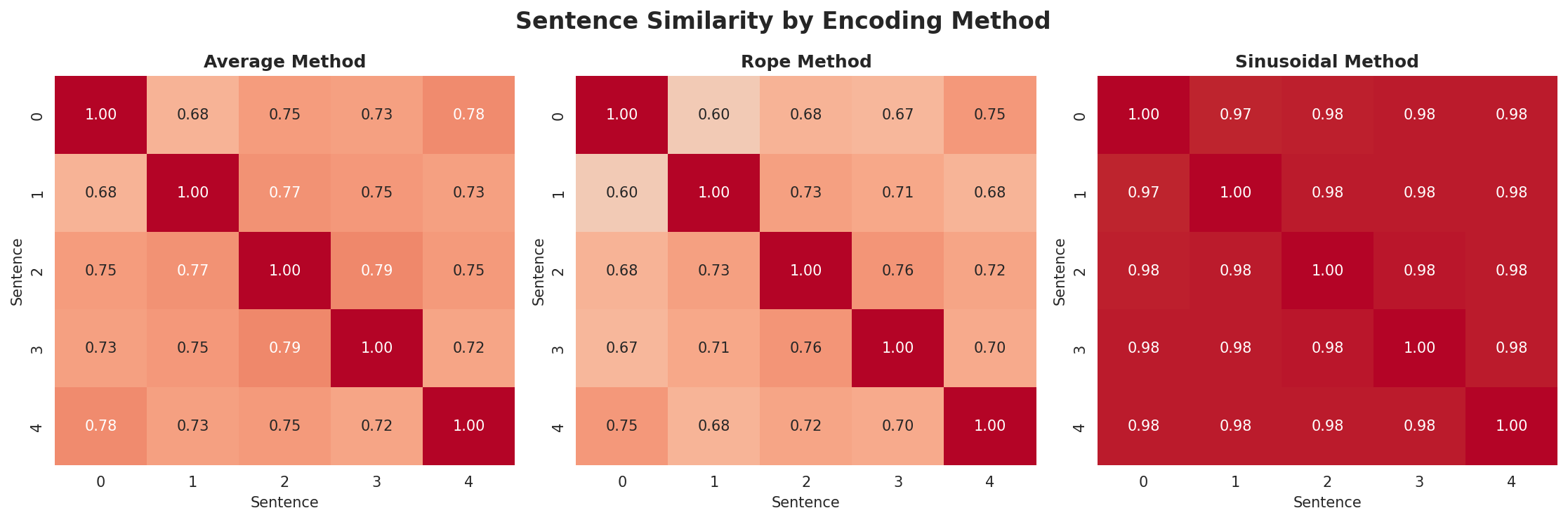
- Xet hash:
- ac5214786e813137e7b1c4594e51051d1e5247f0ecf2b94e862e5fd6f8c80369
- Size of remote file:
- 106 kB
- SHA256:
- 2c322f5f0e15011715593452b479ce3ecc2897ca9cd4792f3173771cf4115f70
·
Xet efficiently stores Large Files inside Git, intelligently splitting files into unique chunks and accelerating uploads and downloads. More info.