Spaces:
Build error

Build error
Add application file
Browse files- .gitattributes +3 -0
- Dockerfile +19 -0
- app_streamlit.py +173 -0
- attention_model_state.pth +3 -0
- caption.py +120 -0
- dataset.py +91 -0
- download_files.py +33 -0
- imgs/Slide1.PNG +3 -0
- imgs/Slide2.PNG +3 -0
- imgs/Slide3.PNG +3 -0
- imgs/Slide4.PNG +3 -0
- imgs/Slide5.PNG +3 -0
- imgs/Slide6.PNG +3 -0
- imgs/appSS00.png +3 -0
- imgs/appSS01.png +3 -0
- imgs/appSS02.png +3 -0
- imgs/appSS04.png +3 -0
- imgs/appSS05.png +3 -0
- imgs/losses.png +3 -0
- imgs/raw_imgs/img_00.png +3 -0
- imgs/raw_imgs/img_01.png +3 -0
- imgs/raw_imgs/img_02.png +3 -0
- imgs/raw_imgs/img_03.png +3 -0
- imgs/raw_imgs/img_04.png +3 -0
- imgs/raw_imgs/img_05.png +3 -0
- imgs/raw_imgs/img_06.png +3 -0
- imgs/raw_imgs/img_07.png +3 -0
- imgs/raw_imgs/img_a00.png +3 -0
- imgs/raw_imgs/img_a01.png +3 -0
- imgs/raw_imgs/img_a02.png +3 -0
- imgs/raw_imgs/img_a03.png +3 -0
- imgs/raw_imgs/img_a04.png +3 -0
- imgs/raw_imgs/img_a05.png +3 -0
- imgs/raw_imgs/img_a06.png +3 -0
- imgs/raw_imgs/img_a07.png +3 -0
- imgs/test2.jpeg +3 -0
- model.py +134 -0
- packages.txt +1 -0
- requirements.txt +0 -0
- train.py +160 -0
- utils.py +51 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
Dockerfile
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.9
|
| 2 |
+
|
| 3 |
+
# Buat user non-root
|
| 4 |
+
RUN useradd -m -u 1000 user
|
| 5 |
+
USER user
|
| 6 |
+
ENV PATH="/home/user/.local/bin:$PATH"
|
| 7 |
+
|
| 8 |
+
# Set direktori kerja
|
| 9 |
+
WORKDIR /app
|
| 10 |
+
|
| 11 |
+
# Salin dependencies dan install
|
| 12 |
+
COPY --chown=user ./requirements.txt requirements.txt
|
| 13 |
+
RUN pip install --no-cache-dir --upgrade -r requirements.txt
|
| 14 |
+
|
| 15 |
+
# Salin semua file app ke image
|
| 16 |
+
COPY --chown=user . /app
|
| 17 |
+
|
| 18 |
+
# Jalankan aplikasi Streamlit
|
| 19 |
+
CMD ["streamlit", "run", "app_streamlit.py", "--server.port=7860", "--server.address=0.0.0.0"]
|
app_streamlit.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
from transformers import BlipProcessor, BlipForConditionalGeneration
|
| 6 |
+
from transformers import AutoProcessor, AutoModelForVisualQuestionAnswering
|
| 7 |
+
from PIL import Image, ImageOps
|
| 8 |
+
import io
|
| 9 |
+
import torchvision.transforms as T
|
| 10 |
+
import torch.nn.functional as F
|
| 11 |
+
|
| 12 |
+
# **Cek Device**
|
| 13 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 14 |
+
|
| 15 |
+
# **Konfigurasi Halaman Streamlit**
|
| 16 |
+
st.set_page_config(
|
| 17 |
+
initial_sidebar_state="expanded",
|
| 18 |
+
page_title="Explainable Image Caption Bot"
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
# **Load Model BLIP**
|
| 22 |
+
@st.cache_resource
|
| 23 |
+
def load_blip_model():
|
| 24 |
+
# processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
|
| 25 |
+
# model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base").to(device)
|
| 26 |
+
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
|
| 27 |
+
model = AutoModelForVisualQuestionAnswering.from_pretrained("Salesforce/blip2-opt-2.7b").to(device)
|
| 28 |
+
return processor, model
|
| 29 |
+
|
| 30 |
+
processor, model = load_blip_model()
|
| 31 |
+
|
| 32 |
+
# **Transformasi Gambar untuk Model**
|
| 33 |
+
def transform_image(img):
|
| 34 |
+
transform = T.Compose([
|
| 35 |
+
T.Resize((384, 384)), # Resize sesuai model BLIP
|
| 36 |
+
T.ToTensor(),
|
| 37 |
+
T.Normalize((0.5,), (0.5,))
|
| 38 |
+
])
|
| 39 |
+
return transform(img)
|
| 40 |
+
|
| 41 |
+
def generate_caption(image, processor, model):
|
| 42 |
+
inputs = processor(images=image, return_tensors="pt").to(device)
|
| 43 |
+
|
| 44 |
+
# Pastikan kita menangkap perhatian dari Transformer
|
| 45 |
+
attention_maps = []
|
| 46 |
+
|
| 47 |
+
def get_attention_hook(module, input, output):
|
| 48 |
+
print("✅ Hook executed! Attention captured.") # Debugging
|
| 49 |
+
attention_maps.append(output) # Output adalah tuple
|
| 50 |
+
|
| 51 |
+
# Pasang hook ke layer yang sesuai
|
| 52 |
+
handle = model.vision_model.encoder.layers[-1].self_attn.register_forward_hook(get_attention_hook)
|
| 53 |
+
|
| 54 |
+
# Generate caption
|
| 55 |
+
with torch.no_grad():
|
| 56 |
+
caption_ids = model.generate(**inputs)
|
| 57 |
+
|
| 58 |
+
# Hapus hook setelah digunakan
|
| 59 |
+
handle.remove()
|
| 60 |
+
|
| 61 |
+
caption = processor.decode(caption_ids[0], skip_special_tokens=True)
|
| 62 |
+
|
| 63 |
+
# **Periksa apakah attention_maps berhasil ditangkap**
|
| 64 |
+
if not attention_maps:
|
| 65 |
+
print("❌ Attention Maps tidak terisi! Hook mungkin tidak bekerja.")
|
| 66 |
+
return caption, None
|
| 67 |
+
|
| 68 |
+
# **Ambil tensor dari tuple**
|
| 69 |
+
attention_tensor = attention_maps[0][0] # Ambil tensor pertama dari tuple
|
| 70 |
+
attention = attention_tensor.cpu().detach().numpy().mean(axis=1)
|
| 71 |
+
|
| 72 |
+
return caption, attention
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# **Fungsi untuk Memuat Gambar**
|
| 76 |
+
@st.cache_data
|
| 77 |
+
def load_uploaded_image(img):
|
| 78 |
+
if isinstance(img, str):
|
| 79 |
+
image = Image.open(img)
|
| 80 |
+
else:
|
| 81 |
+
img_bytes = img.read()
|
| 82 |
+
image = Image.open(io.BytesIO(img_bytes)).convert("RGB")
|
| 83 |
+
|
| 84 |
+
image = ImageOps.exif_transpose(image) # Perbaiki orientasi gambar
|
| 85 |
+
return image
|
| 86 |
+
|
| 87 |
+
def plot_attention(image, caption, attention):
|
| 88 |
+
"""
|
| 89 |
+
Menampilkan heatmap attention untuk setiap kata dalam caption.
|
| 90 |
+
"""
|
| 91 |
+
|
| 92 |
+
if attention is None or len(attention.shape) != 2:
|
| 93 |
+
st.error("Attention map tidak valid! Tidak bisa menampilkan heatmap.")
|
| 94 |
+
return
|
| 95 |
+
|
| 96 |
+
num_words = len(caption.split())
|
| 97 |
+
num_attention_steps = min(num_words, attention.shape[0]) # Sesuaikan panjang attention
|
| 98 |
+
|
| 99 |
+
fig, axes = plt.subplots(1, num_attention_steps, figsize=(num_attention_steps * 3, 5))
|
| 100 |
+
|
| 101 |
+
if num_attention_steps == 1:
|
| 102 |
+
axes = [axes] # Pastikan list jika hanya ada satu kata
|
| 103 |
+
|
| 104 |
+
for i in range(num_attention_steps):
|
| 105 |
+
attn_map = attention[i]
|
| 106 |
+
|
| 107 |
+
# **Reshape attention ke bentuk yang sesuai**
|
| 108 |
+
if attn_map.shape[0] == 768:
|
| 109 |
+
grid_size = 24 # Vision Transformer biasanya menggunakan 24x32 patches
|
| 110 |
+
attn_map = attn_map[:grid_size * grid_size].reshape(grid_size, grid_size)
|
| 111 |
+
else:
|
| 112 |
+
st.warning(f"Attention map tidak bisa diubah menjadi grid! (Token count: {attn_map.shape[0]})")
|
| 113 |
+
continue
|
| 114 |
+
|
| 115 |
+
# **Interpolasi agar ukuran sesuai dengan gambar**
|
| 116 |
+
attn_resized = F.interpolate(
|
| 117 |
+
torch.tensor(attn_map).unsqueeze(0).unsqueeze(0),
|
| 118 |
+
size=(image.size[1], image.size[0]), # Sesuaikan ke ukuran gambar
|
| 119 |
+
mode="bilinear",
|
| 120 |
+
align_corners=False
|
| 121 |
+
).squeeze().numpy()
|
| 122 |
+
|
| 123 |
+
# **Plot setiap heatmap per kata**
|
| 124 |
+
axes[i].imshow(image)
|
| 125 |
+
axes[i].imshow(attn_resized, cmap='jet', alpha=0.5)
|
| 126 |
+
axes[i].set_title(caption.split()[i])
|
| 127 |
+
axes[i].axis("off")
|
| 128 |
+
|
| 129 |
+
plt.tight_layout()
|
| 130 |
+
st.pyplot(fig)
|
| 131 |
+
|
| 132 |
+
# **Streamlit UI**
|
| 133 |
+
st.title("Explainable Image Captioning Bot 🤖🖼️")
|
| 134 |
+
st.text("Powered by BLIP (Salesforce) - A Transformer-based Image Captioning Model")
|
| 135 |
+
|
| 136 |
+
st.success("Upload an image and generate a caption!")
|
| 137 |
+
|
| 138 |
+
# **File Upload**
|
| 139 |
+
uploaded_file = st.file_uploader("Upload an image (JPG, PNG, JPEG)", type=["png", "jpg", "jpeg", "webp"])
|
| 140 |
+
img_path = "imgs/test2.jpeg" if uploaded_file is None else uploaded_file
|
| 141 |
+
|
| 142 |
+
# **Muat dan Tampilkan Gambar**
|
| 143 |
+
image = load_uploaded_image(img_path)
|
| 144 |
+
st.image(image, use_column_width=True, caption="Uploaded Image")
|
| 145 |
+
|
| 146 |
+
# **Generate Caption Button**
|
| 147 |
+
# Jika tombol ditekan, jalankan captioning dan attention visualization
|
| 148 |
+
if st.button("Generate Caption"):
|
| 149 |
+
caption, attention = generate_caption(image, processor, model)
|
| 150 |
+
|
| 151 |
+
if attention is None:
|
| 152 |
+
st.error("Attention map tidak tersedia! Coba ganti layer yang di-hook.")
|
| 153 |
+
else:
|
| 154 |
+
st.markdown(f"### **Generated Caption:**\n📢 *{caption}*")
|
| 155 |
+
plot_attention(image, caption, attention) # ✅ Panggil dengan 3 argumen
|
| 156 |
+
|
| 157 |
+
st.balloons()
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
# **Sidebar Info**
|
| 161 |
+
st.sidebar.markdown("""
|
| 162 |
+
### About This App 📝
|
| 163 |
+
This app generates captions for images using **Hugging Face's BLIP model** trained by **Salesforce**.
|
| 164 |
+
It also provides **explainable AI insights** into how images are understood by deep learning models.
|
| 165 |
+
|
| 166 |
+
### How to Use:
|
| 167 |
+
1. **Upload an image** 📷 (JPG/PNG/JPEG).
|
| 168 |
+
2. **Click "Generate Caption"** 🏷️.
|
| 169 |
+
3. **View AI-generated caption** for your image along with **attention heatmap**!
|
| 170 |
+
|
| 171 |
+
### Want More Features?
|
| 172 |
+
Check the model on [Hugging Face](https://huggingface.co/Salesforce/blip-image-captioning-base).
|
| 173 |
+
""")
|
attention_model_state.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:83319fd76020f7b4a562b0b607c8b89fc8a604b5d385d72ea38c4b1b9c36d5b4
|
| 3 |
+
size 230166330
|
caption.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from nltk.translate.bleu_score import corpus_bleu
|
| 2 |
+
from tqdm import tqdm
|
| 3 |
+
from dataset import Vocabulary
|
| 4 |
+
from skimage import transform
|
| 5 |
+
from model import *
|
| 6 |
+
from utils import *
|
| 7 |
+
import torchvision.transforms as T
|
| 8 |
+
from PIL import Image
|
| 9 |
+
import argparse
|
| 10 |
+
|
| 11 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
# Will only work for batch size 1
|
| 15 |
+
def get_all_captions(img, model, vocab=None):
|
| 16 |
+
features = model.EncoderCNN(img[0:1].to(device))
|
| 17 |
+
caps, alphas = model.DecoderLSTM.gen_captions(features, vocab=vocab)
|
| 18 |
+
caps = caps[:-2]
|
| 19 |
+
return caps
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def calculate_bleu_score(dataloader, model, vocab):
|
| 23 |
+
candidate_corpus = []
|
| 24 |
+
references_corpus = []
|
| 25 |
+
|
| 26 |
+
for batch in tqdm(dataloader, total=len(dataloader)):
|
| 27 |
+
img, cap, all_caps = batch
|
| 28 |
+
img, cap = img.to(device), cap.to(device)
|
| 29 |
+
caps = get_all_captions(img, model, vocab)
|
| 30 |
+
candidate_corpus.append(caps)
|
| 31 |
+
references_corpus.append(all_caps[0])
|
| 32 |
+
|
| 33 |
+
assert len(candidate_corpus) == len(references_corpus)
|
| 34 |
+
print(f"\nBLEU1 = {corpus_bleu(references_corpus, candidate_corpus, (1, 0, 0, 0))}")
|
| 35 |
+
print(f"BLEU2 = {corpus_bleu(references_corpus, candidate_corpus, (0.5, 0.5, 0, 0))}")
|
| 36 |
+
print(f"BLEU3 = {corpus_bleu(references_corpus, candidate_corpus, (0.33, 0.33, 0.33, 0))}")
|
| 37 |
+
print(f"BLEU4 = {corpus_bleu(references_corpus, candidate_corpus, (0.25, 0.25, 0.25, 0.25))}")
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def get_caps_from(features_tensors, model, vocab=None):
|
| 41 |
+
model.eval()
|
| 42 |
+
with torch.no_grad():
|
| 43 |
+
features = model.EncoderCNN(features_tensors[0:1].to(device))
|
| 44 |
+
caps, alphas = model.DecoderLSTM.gen_captions(features, vocab=vocab)
|
| 45 |
+
caption = ' '.join(caps)
|
| 46 |
+
show_img(features_tensors[0], caption)
|
| 47 |
+
|
| 48 |
+
return caps, alphas
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def plot_attention(img, target, attention_plot):
|
| 52 |
+
img = img.to('cpu').numpy().transpose((1, 2, 0))
|
| 53 |
+
temp_image = img
|
| 54 |
+
|
| 55 |
+
fig = plt.figure(figsize=(15, 15))
|
| 56 |
+
len_caps = len(target)
|
| 57 |
+
for i in range(len_caps):
|
| 58 |
+
temp_att = attention_plot[i].reshape(7, 7)
|
| 59 |
+
temp_att = transform.pyramid_expand(temp_att, upscale=24, sigma=8)
|
| 60 |
+
ax = fig.add_subplot(len_caps // 2, len_caps // 2, i + 1)
|
| 61 |
+
ax.set_title(target[i])
|
| 62 |
+
img = ax.imshow(temp_image)
|
| 63 |
+
ax.imshow(temp_att, cmap='gray', alpha=0.5, extent=img.get_extent())
|
| 64 |
+
|
| 65 |
+
plt.tight_layout()
|
| 66 |
+
plt.show()
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def plot_caption_with_attention(img_pth, model, transforms_=None, vocab=None):
|
| 70 |
+
img = Image.open(img_pth)
|
| 71 |
+
img = transforms_(img)
|
| 72 |
+
img.unsqueeze_(0)
|
| 73 |
+
caps, attention = get_caps_from(img, model, vocab)
|
| 74 |
+
plot_attention(img[0], caps, attention)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def main(arguments):
|
| 78 |
+
state_checkpoint = torch.load(arguments.state_chechpoint, map_location=device) # change paths
|
| 79 |
+
# model params
|
| 80 |
+
vocab = state_checkpoint['vocab']
|
| 81 |
+
embed_size = arguments.embed_size
|
| 82 |
+
embed_wts = None
|
| 83 |
+
vocab_size = state_checkpoint['vocab_size']
|
| 84 |
+
attention_dim = arguments.attention_dim
|
| 85 |
+
encoder_dim = arguments.encoder_dim
|
| 86 |
+
decoder_dim = arguments.decoder_dim
|
| 87 |
+
fc_dims = arguments.fc_dims
|
| 88 |
+
|
| 89 |
+
model = EncoderDecoder(embed_size,
|
| 90 |
+
vocab_size,
|
| 91 |
+
attention_dim,
|
| 92 |
+
encoder_dim,
|
| 93 |
+
decoder_dim,
|
| 94 |
+
fc_dims,
|
| 95 |
+
p=0.3,
|
| 96 |
+
embeddings=embed_wts).to(device)
|
| 97 |
+
|
| 98 |
+
model.load_state_dict(state_checkpoint['state_dict'])
|
| 99 |
+
|
| 100 |
+
transforms = T.Compose([
|
| 101 |
+
T.Resize((224, 224)),
|
| 102 |
+
T.ToTensor(),
|
| 103 |
+
T.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
|
| 104 |
+
])
|
| 105 |
+
|
| 106 |
+
img_path = arguments.image
|
| 107 |
+
plot_caption_with_attention(img_path, model, transforms, vocab)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
if __name__ == "__main__":
|
| 111 |
+
parser = argparse.ArgumentParser()
|
| 112 |
+
parser.add_argument('--image', type=str, required=True, help='input image for generating caption')
|
| 113 |
+
parser.add_argument('--state_checkpoint', type=str, required=True, help='path for state checkpoint')
|
| 114 |
+
parser.add_argument('--embed_size', type=int, default=300, help='dimension of word embedding vectors')
|
| 115 |
+
parser.add_argument('--attention_dim', type=int, default=256, help='dimension of attention layer')
|
| 116 |
+
parser.add_argument('--encoder_dim', type=int, default=2048, help='dimension of encoder layer')
|
| 117 |
+
parser.add_argument('--decoder_dim', type=int, default=512, help='dimension of decoder layer')
|
| 118 |
+
parser.add_argument('--fc_dims', type=int, default=256, help='dimension of fully connected layer')
|
| 119 |
+
args = parser.parse_args()
|
| 120 |
+
main(args)
|
dataset.py
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import pandas as pd
|
| 3 |
+
from torch.nn.utils.rnn import pad_sequence
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import spacy
|
| 6 |
+
import os
|
| 7 |
+
|
| 8 |
+
from torch.utils.data import Dataset
|
| 9 |
+
|
| 10 |
+
spacy_eng = spacy.load('en_core_web_sm')
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Vocabulary:
|
| 14 |
+
def __init__(self, freq_threshold=5):
|
| 15 |
+
self.freq_threshold = freq_threshold
|
| 16 |
+
self.itos = {0: "<PAD>", 1: "<SOS>", 2: "<EOS>", 3: "<UNK>"}
|
| 17 |
+
self.stoi = {v: k for k, v in self.itos.items()}
|
| 18 |
+
|
| 19 |
+
def __len__(self):
|
| 20 |
+
return len(self.itos)
|
| 21 |
+
|
| 22 |
+
@staticmethod
|
| 23 |
+
def tokenize(text):
|
| 24 |
+
return [token.text.lower() for token in spacy_eng.tokenizer(text)]
|
| 25 |
+
|
| 26 |
+
def build_vocab(self, sent_list):
|
| 27 |
+
freqs = {}
|
| 28 |
+
idx = 4
|
| 29 |
+
for sent in sent_list:
|
| 30 |
+
for word in self.tokenize(sent):
|
| 31 |
+
if word not in freqs:
|
| 32 |
+
freqs[word] = 1
|
| 33 |
+
else:
|
| 34 |
+
freqs[word] += 1
|
| 35 |
+
|
| 36 |
+
if freqs[word] == self.freq_threshold:
|
| 37 |
+
self.itos[idx] = word
|
| 38 |
+
self.stoi[word] = idx
|
| 39 |
+
idx += 1
|
| 40 |
+
|
| 41 |
+
def numericalize(self, sents):
|
| 42 |
+
tokens = self.tokenize(sents)
|
| 43 |
+
return [self.stoi[token] if token in self.stoi else self.stoi["<UNK>"]
|
| 44 |
+
for token in tokens]
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class FlickrDataset(Dataset):
|
| 48 |
+
def __init__(self, root_dir, csv_file, transforms=None, freq_threshold=5):
|
| 49 |
+
self.root_dir = root_dir
|
| 50 |
+
self.df = pd.read_csv(csv_file)
|
| 51 |
+
self.transforms = transforms
|
| 52 |
+
|
| 53 |
+
self.img_pts = self.df.iloc[:, 0]
|
| 54 |
+
self.caps = self.df.iloc[:, 1]
|
| 55 |
+
self.vocab = Vocabulary(freq_threshold)
|
| 56 |
+
self.vocab.build_vocab(self.caps.tolist())
|
| 57 |
+
|
| 58 |
+
def __len__(self):
|
| 59 |
+
return len(self.df)
|
| 60 |
+
|
| 61 |
+
def __getitem__(self, idx):
|
| 62 |
+
captions = self.caps[idx]
|
| 63 |
+
img_pt = self.img_pts[idx]
|
| 64 |
+
|
| 65 |
+
img = Image.open(os.path.join(self.root_dir, img_pt)).convert('RGB')
|
| 66 |
+
|
| 67 |
+
if self.transforms is not None:
|
| 68 |
+
img = self.transforms(img)
|
| 69 |
+
|
| 70 |
+
encoded_cap = []
|
| 71 |
+
encoded_cap += [self.vocab.stoi["<SOS>"]] # stoi string to index
|
| 72 |
+
encoded_cap += self.vocab.numericalize(captions)
|
| 73 |
+
encoded_cap += [self.vocab.stoi["<EOS>"]]
|
| 74 |
+
encoded_cap = torch.LongTensor(encoded_cap)
|
| 75 |
+
|
| 76 |
+
return img, encoded_cap
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class CapsCollate:
|
| 80 |
+
def __init__(self, pad_idx, batch_first=False):
|
| 81 |
+
self.pad_idx = pad_idx
|
| 82 |
+
self.batch_first = batch_first
|
| 83 |
+
|
| 84 |
+
def __call__(self, batch):
|
| 85 |
+
imgs = [item[0].unsqueeze(0) for item in batch]
|
| 86 |
+
imgs = torch.cat(imgs, dim=0)
|
| 87 |
+
|
| 88 |
+
targets = [item[1] for item in batch]
|
| 89 |
+
targets = pad_sequence(targets, batch_first=self.batch_first, padding_value=self.pad_idx)
|
| 90 |
+
|
| 91 |
+
return imgs, targets
|
download_files.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def download_file_from_google_drive(id, destination):
|
| 5 |
+
URL = "https://docs.google.com/uc?export=download"
|
| 6 |
+
|
| 7 |
+
session = requests.Session()
|
| 8 |
+
|
| 9 |
+
response = session.get(URL, params={'id': id}, stream=True)
|
| 10 |
+
token = get_confirm_token(response)
|
| 11 |
+
|
| 12 |
+
if token:
|
| 13 |
+
params = {'id': id, 'confirm': token}
|
| 14 |
+
response = session.get(URL, params=params, stream=True)
|
| 15 |
+
|
| 16 |
+
save_response_content(response, destination)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_confirm_token(response):
|
| 20 |
+
for key, value in response.cookies.items():
|
| 21 |
+
if key.startswith('download_warning'):
|
| 22 |
+
return value
|
| 23 |
+
|
| 24 |
+
return None
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def save_response_content(response, destination):
|
| 28 |
+
CHUNK_SIZE = 32768
|
| 29 |
+
|
| 30 |
+
with open(destination, "wb") as f:
|
| 31 |
+
for chunk in response.iter_content(CHUNK_SIZE):
|
| 32 |
+
if chunk: # filter out keep-alive new chunks
|
| 33 |
+
f.write(chunk)
|
imgs/Slide1.PNG
ADDED

|
Git LFS Details
|
imgs/Slide2.PNG
ADDED

|
Git LFS Details
|
imgs/Slide3.PNG
ADDED

|
Git LFS Details
|
imgs/Slide4.PNG
ADDED

|
Git LFS Details
|
imgs/Slide5.PNG
ADDED

|
Git LFS Details
|
imgs/Slide6.PNG
ADDED

|
Git LFS Details
|
imgs/appSS00.png
ADDED

|
Git LFS Details
|
imgs/appSS01.png
ADDED

|
Git LFS Details
|
imgs/appSS02.png
ADDED

|
Git LFS Details
|
imgs/appSS04.png
ADDED

|
Git LFS Details
|
imgs/appSS05.png
ADDED

|
Git LFS Details
|
imgs/losses.png
ADDED
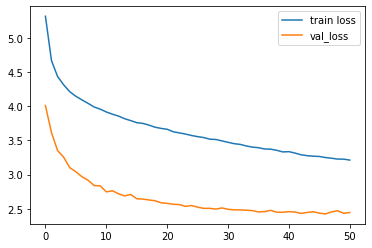
|
Git LFS Details
|
imgs/raw_imgs/img_00.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_01.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_02.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_03.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_04.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_05.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_06.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_07.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_a00.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_a01.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_a02.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_a03.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_a04.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_a05.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_a06.png
ADDED

|
Git LFS Details
|
imgs/raw_imgs/img_a07.png
ADDED

|
Git LFS Details
|
imgs/test2.jpeg
ADDED

|
Git LFS Details
|
model.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import torchvision.models as models
|
| 5 |
+
|
| 6 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Encoder(nn.Module):
|
| 10 |
+
def __init__(self):
|
| 11 |
+
super(Encoder, self).__init__()
|
| 12 |
+
resnet = models.resnet50(pretrained=True)
|
| 13 |
+
for param in resnet.parameters():
|
| 14 |
+
param.requires_grad_(False)
|
| 15 |
+
|
| 16 |
+
modules = list(resnet.children())[:-2] # extracting the last conv layer from the model
|
| 17 |
+
self.resnet = nn.Sequential(*modules)
|
| 18 |
+
|
| 19 |
+
def forward(self, imgs):
|
| 20 |
+
features = self.resnet(imgs)
|
| 21 |
+
features = features.permute(0, 2, 3, 1) # batch x 7 x 7 x 2048
|
| 22 |
+
features = features.view(features.size(0), -1, features.size(-1)) # batch x 49 x 2048
|
| 23 |
+
return features
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class Attention(nn.Module):
|
| 27 |
+
def __init__(self, encoder_dims, decoder_dims, attention_dims):
|
| 28 |
+
super(Attention, self).__init__()
|
| 29 |
+
self.attention_dims = attention_dims # size of attention network
|
| 30 |
+
self.U = nn.Linear(encoder_dims, attention_dims) # a^(t)
|
| 31 |
+
self.W = nn.Linear(decoder_dims, attention_dims) # s^(t` - 1)
|
| 32 |
+
self.A = nn.Linear(attention_dims, 1) # cvt the attention dims back to 1
|
| 33 |
+
|
| 34 |
+
def forward(self, features, hidden):
|
| 35 |
+
u_as = self.U(features)
|
| 36 |
+
w_as = self.W(hidden)
|
| 37 |
+
combined_state = torch.tanh(u_as + w_as.unsqueeze(1))
|
| 38 |
+
attention_score = self.A(combined_state)
|
| 39 |
+
attention_score = attention_score.squeeze(2)
|
| 40 |
+
alpha = F.softmax(attention_score, dim=1)
|
| 41 |
+
attention_weights = features * alpha.unsqueeze(2) # batch x num_timesteps (49) x features
|
| 42 |
+
attention_weights = attention_weights.sum(dim=1)
|
| 43 |
+
return alpha, attention_weights
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class Decoder(nn.Module):
|
| 47 |
+
def __init__(self, embed_size, vocab_size, attention_dim, encoder_dim, decoder_dim, fc_dims, p=0.3,
|
| 48 |
+
embeddings=None):
|
| 49 |
+
super().__init__()
|
| 50 |
+
|
| 51 |
+
self.vocab_size = vocab_size
|
| 52 |
+
self.attention_dim = attention_dim
|
| 53 |
+
self.decoder_dim = decoder_dim
|
| 54 |
+
|
| 55 |
+
self.embedding = nn.Embedding(vocab_size, embedding_dim=embed_size)
|
| 56 |
+
self.attention = Attention(encoder_dim, decoder_dim, attention_dim)
|
| 57 |
+
|
| 58 |
+
self.init_h = nn.Linear(encoder_dim, decoder_dim)
|
| 59 |
+
self.init_c = nn.Linear(encoder_dim, decoder_dim)
|
| 60 |
+
self.lstm = nn.LSTMCell(encoder_dim + embed_size, decoder_dim, bias=True)
|
| 61 |
+
self.fcn1 = nn.Linear(decoder_dim, vocab_size)
|
| 62 |
+
self.fcn2 = nn.Linear(fc_dims, vocab_size)
|
| 63 |
+
self.drop = nn.Dropout(p)
|
| 64 |
+
|
| 65 |
+
if embeddings is not None:
|
| 66 |
+
self.load_pretrained_embed(embeddings)
|
| 67 |
+
|
| 68 |
+
def forward(self, features, captions):
|
| 69 |
+
|
| 70 |
+
seq_length = len(captions[0]) - 1 # Exclude the last one
|
| 71 |
+
batch_size = captions.size(0)
|
| 72 |
+
num_timesteps = features.size(1)
|
| 73 |
+
|
| 74 |
+
embed = self.embedding(captions)
|
| 75 |
+
h, c = self.init_hidden_state(features) # initialize h and c for LSTM
|
| 76 |
+
|
| 77 |
+
preds = torch.zeros(batch_size, seq_length, self.vocab_size).to(device)
|
| 78 |
+
alphas = torch.zeros(batch_size, seq_length, num_timesteps).to(device)
|
| 79 |
+
|
| 80 |
+
for s in range(seq_length):
|
| 81 |
+
alpha, context = self.attention(features, h)
|
| 82 |
+
lstm_inp = torch.cat((embed[:, s], context), dim=1)
|
| 83 |
+
h, c = self.lstm(lstm_inp, (h, c))
|
| 84 |
+
out = self.drop(self.fcn1(h))
|
| 85 |
+
preds[:, s] = out
|
| 86 |
+
alphas[:, s] = alpha
|
| 87 |
+
|
| 88 |
+
return preds, alphas
|
| 89 |
+
|
| 90 |
+
def gen_captions(self, features, max_len=20, vocab=None):
|
| 91 |
+
h, c = self.init_hidden_state(features)
|
| 92 |
+
alphas = []
|
| 93 |
+
captions = []
|
| 94 |
+
word = torch.tensor(vocab.stoi["<SOS>"]).view(1, -1).to(device)
|
| 95 |
+
embed = self.embedding(word)
|
| 96 |
+
for i in range(max_len):
|
| 97 |
+
alpha, context = self.attention(features, h)
|
| 98 |
+
alphas.append(alpha.cpu().detach().numpy())
|
| 99 |
+
|
| 100 |
+
lstm_inp = torch.cat((embed[:, 0], context), dim=1)
|
| 101 |
+
h, c = self.lstm(lstm_inp, (h, c))
|
| 102 |
+
out = self.drop(self.fcn1(h))
|
| 103 |
+
word_out_idx = torch.argmax(out, dim=1)
|
| 104 |
+
captions.append(word_out_idx.item())
|
| 105 |
+
if vocab.itos[word_out_idx.item()] == "<EOS>":
|
| 106 |
+
break
|
| 107 |
+
embed = self.embedding(word_out_idx.unsqueeze(0))
|
| 108 |
+
|
| 109 |
+
return [vocab.itos[word] for word in captions], alphas
|
| 110 |
+
|
| 111 |
+
def load_pretrained_embed(self, embeddings):
|
| 112 |
+
self.embedding.weight = nn.Parameter(embeddings)
|
| 113 |
+
for p in self.embedding.parameters():
|
| 114 |
+
p.requires_grad = True
|
| 115 |
+
|
| 116 |
+
def init_hidden_state(self, encoder_output):
|
| 117 |
+
mean_encoder_out = encoder_output.mean(dim=1)
|
| 118 |
+
h = self.init_h(mean_encoder_out)
|
| 119 |
+
c = self.init_c(mean_encoder_out)
|
| 120 |
+
return h, c
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
class EncoderDecoder(nn.Module):
|
| 124 |
+
def __init__(self, embed_size, vocab_size, attention_dim, encoder_dim, decoder_dim, fc_dims, p=0.3,
|
| 125 |
+
embeddings=None):
|
| 126 |
+
super().__init__()
|
| 127 |
+
self.EncoderCNN = Encoder()
|
| 128 |
+
self.DecoderLSTM = Decoder(embed_size, vocab_size, attention_dim, encoder_dim, decoder_dim, fc_dims, p,
|
| 129 |
+
embeddings)
|
| 130 |
+
|
| 131 |
+
def forward(self, imgs, caps):
|
| 132 |
+
features = self.EncoderCNN(imgs)
|
| 133 |
+
out = self.DecoderLSTM(features, caps)
|
| 134 |
+
return out
|
packages.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
wget
|
requirements.txt
ADDED
|
Binary file (3.57 kB). View file
|
|
|
train.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torchvision.transforms as T
|
| 2 |
+
from torch import optim
|
| 3 |
+
from torch.utils.data import DataLoader
|
| 4 |
+
from torch.utils.data import random_split
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
|
| 7 |
+
from dataset import *
|
| 8 |
+
from model import *
|
| 9 |
+
from utils import *
|
| 10 |
+
|
| 11 |
+
spacy_eng = spacy.load('en')
|
| 12 |
+
|
| 13 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 14 |
+
# init seed
|
| 15 |
+
seed = torch.randint(100, (1,))
|
| 16 |
+
torch.manual_seed(seed)
|
| 17 |
+
shuffle = True
|
| 18 |
+
# src folders
|
| 19 |
+
root_folder = "/content/flickr8k/Images" # change this
|
| 20 |
+
csv_file = "/content/flickr8k/captions.txt" # change this
|
| 21 |
+
|
| 22 |
+
# image transforms and augmentation
|
| 23 |
+
transforms = T.Compose([
|
| 24 |
+
T.Resize(226),
|
| 25 |
+
T.RandomCrop(224),
|
| 26 |
+
T.ToTensor(),
|
| 27 |
+
T.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
|
| 28 |
+
])
|
| 29 |
+
|
| 30 |
+
# define dataset
|
| 31 |
+
dataset = FlickrDataset(root_folder, csv_file, transforms)
|
| 32 |
+
|
| 33 |
+
# split dataset
|
| 34 |
+
val_size = 512
|
| 35 |
+
test_size = 256
|
| 36 |
+
train_size = len(dataset) - val_size - test_size
|
| 37 |
+
train_ds, val_ds, test_ds = random_split(dataset,
|
| 38 |
+
[train_size, val_size, test_size])
|
| 39 |
+
|
| 40 |
+
# Define data loader parameters
|
| 41 |
+
num_workers = 4
|
| 42 |
+
pin_memory = True
|
| 43 |
+
batch_size_train = 256
|
| 44 |
+
batch_size_val_test = 128
|
| 45 |
+
pad_idx = dataset.vocab.stoi["<PAD>"]
|
| 46 |
+
|
| 47 |
+
# define loaders
|
| 48 |
+
dataloader_train = DataLoader(train_ds,
|
| 49 |
+
batch_size=batch_size_train,
|
| 50 |
+
pin_memory=pin_memory,
|
| 51 |
+
num_workers=num_workers,
|
| 52 |
+
shuffle=shuffle,
|
| 53 |
+
collate_fn=CapsCollate(pad_idx=pad_idx, batch_first=True))
|
| 54 |
+
dataloader_validation = DataLoader(val_ds,
|
| 55 |
+
batch_size=batch_size_val_test,
|
| 56 |
+
pin_memory=pin_memory,
|
| 57 |
+
num_workers=num_workers,
|
| 58 |
+
shuffle=shuffle,
|
| 59 |
+
collate_fn=CapsCollate(pad_idx=pad_idx, batch_first=True))
|
| 60 |
+
dataloader_test = DataLoader(test_ds,
|
| 61 |
+
batch_size=batch_size_val_test,
|
| 62 |
+
pin_memory=pin_memory,
|
| 63 |
+
num_workers=num_workers,
|
| 64 |
+
shuffle=shuffle,
|
| 65 |
+
collate_fn=CapsCollate(pad_idx=pad_idx, batch_first=True))
|
| 66 |
+
|
| 67 |
+
# model parameters
|
| 68 |
+
embed_wts, embed_size = load_embeding("/content/glove.42B.300d.txt", dataset.vocab) # change path
|
| 69 |
+
vocab_size = len(dataset.vocab)
|
| 70 |
+
attention_dim = 256
|
| 71 |
+
encoder_dim = 2048
|
| 72 |
+
decoder_dim = 512
|
| 73 |
+
fc_dims = 256
|
| 74 |
+
learning_rate = 5e-4
|
| 75 |
+
|
| 76 |
+
model = EncoderDecoder(embed_size,
|
| 77 |
+
vocab_size,
|
| 78 |
+
attention_dim,
|
| 79 |
+
encoder_dim,
|
| 80 |
+
decoder_dim,
|
| 81 |
+
fc_dims,
|
| 82 |
+
p=0.3,
|
| 83 |
+
embeddings=embed_wts).to(device)
|
| 84 |
+
loss_fn = nn.CrossEntropyLoss(ignore_index=dataset.vocab.stoi["<PAD>"])
|
| 85 |
+
optimizer = optim.Adam(params=model.parameters(), lr=learning_rate)
|
| 86 |
+
|
| 87 |
+
# training parmeters
|
| 88 |
+
num_epochs = 35
|
| 89 |
+
train_loss_arr = []
|
| 90 |
+
val_loss_arr = []
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def training(dataset, dataloader, loss_criteria, optimize, grad_clip=5.):
|
| 94 |
+
total_loss = 0
|
| 95 |
+
for i, (img, cap) in enumerate(tqdm(dataloader, total=len(dataloader))):
|
| 96 |
+
img, cap = img.to(device), cap.to(device)
|
| 97 |
+
optimize.zero_grad()
|
| 98 |
+
output, attention = model(img, cap)
|
| 99 |
+
targets = cap[:, 1:]
|
| 100 |
+
loss = loss_criteria(output.view(-1, vocab_size), targets.reshape(-1))
|
| 101 |
+
total_loss += (loss.item())
|
| 102 |
+
loss.backward()
|
| 103 |
+
|
| 104 |
+
if grad_clip:
|
| 105 |
+
nn.utils.clip_grad_norm_(model.parameters(), grad_clip)
|
| 106 |
+
|
| 107 |
+
optimize.step()
|
| 108 |
+
|
| 109 |
+
total_loss = total_loss / len(dataloader)
|
| 110 |
+
|
| 111 |
+
return total_loss
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
@torch.no_grad()
|
| 115 |
+
def validate(dataset, dataloader, loss_cr):
|
| 116 |
+
total_loss = 0
|
| 117 |
+
for val_img, val_cap in tqdm(dataloader, total=len(dataloader)):
|
| 118 |
+
val_img, val_cap = val_img.to(device), val_cap.to(device)
|
| 119 |
+
output, attention = model(val_img, val_cap)
|
| 120 |
+
targets = val_cap[:, 1:]
|
| 121 |
+
loss = loss_cr(output.view(-1, vocab_size), targets.reshape(-1))
|
| 122 |
+
total_loss += (loss.item())
|
| 123 |
+
|
| 124 |
+
total_loss /= len(dataloader)
|
| 125 |
+
return total_loss
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
# for see results while training
|
| 129 |
+
@torch.no_grad()
|
| 130 |
+
def test_on_img(data, dataloader):
|
| 131 |
+
dataiter = iter(dataloader)
|
| 132 |
+
img, cap = next(dataiter)
|
| 133 |
+
features = model.EncoderCNN(img[0:1].to(device))
|
| 134 |
+
caps, alphas = model.DecoderLSTM.gen_captions(features, vocab=data.vocab)
|
| 135 |
+
caption = ' '.join(caps)
|
| 136 |
+
show_img(img[0], caption)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def main():
|
| 140 |
+
best_val_loss = 6.0
|
| 141 |
+
for epoch in range(num_epochs):
|
| 142 |
+
print(f"Epoch: {epoch + 1}/{num_epochs}")
|
| 143 |
+
model.train()
|
| 144 |
+
train_loss = training(dataset, dataloader_train, loss_fn, optimizer)
|
| 145 |
+
train_loss_arr.append(train_loss)
|
| 146 |
+
|
| 147 |
+
model.eval()
|
| 148 |
+
val_loss = validate(dataset, dataloader_validation, loss_fn)
|
| 149 |
+
val_loss_arr.append(val_loss)
|
| 150 |
+
print(f"train_loss: {train_loss} validation_loss: {val_loss}")
|
| 151 |
+
test_on_img(dataset, dataloader_validation)
|
| 152 |
+
if len(val_loss_arr) == 1 or val_loss < best_val_loss:
|
| 153 |
+
best_val_loss = val_loss
|
| 154 |
+
save_model(model, epoch, optimizer, train_loss, val_loss, vocab=dataset.vocab)
|
| 155 |
+
print("best model saved successfully")
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
if __name__ == "__main__":
|
| 159 |
+
print(torch.cuda.is_available())
|
| 160 |
+
main()
|
utils.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from matplotlib import pyplot as plt
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def show_img(img, caption):
|
| 7 |
+
img[0] = img[0] * 0.229
|
| 8 |
+
img[1] = img[1] * 0.224
|
| 9 |
+
img[2] = img[2] * 0.225
|
| 10 |
+
img[0] += 0.485
|
| 11 |
+
img[1] += 0.456
|
| 12 |
+
img[2] += 0.406
|
| 13 |
+
img = img.permute(1, 2, 0)
|
| 14 |
+
img = img.to('cpu').numpy()
|
| 15 |
+
plt.imshow(img)
|
| 16 |
+
plt.title(caption)
|
| 17 |
+
plt.show()
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def load_embeding(embed_file, vocab):
|
| 21 |
+
with open(embed_file, 'r') as f:
|
| 22 |
+
embed_dims = len(f.readline().split(' ')) - 1
|
| 23 |
+
|
| 24 |
+
words = set(vocab.stoi.keys())
|
| 25 |
+
embeddings = torch.FloatTensor(len(words), embed_dims)
|
| 26 |
+
bias = np.sqrt(3.0 / embeddings.size(1))
|
| 27 |
+
torch.nn.init.uniform_(embeddings, -bias, bias)
|
| 28 |
+
print("\nLoading embeddings...")
|
| 29 |
+
for line in open(embed_file, 'r'):
|
| 30 |
+
line = line.split(' ')
|
| 31 |
+
emb_word = line[0]
|
| 32 |
+
embedding = list(map(lambda t: float(t), filter(lambda n: n and not n.isspace(), line[1:])))
|
| 33 |
+
# Ignore word if not in train_vocab
|
| 34 |
+
if emb_word not in words:
|
| 35 |
+
continue
|
| 36 |
+
embeddings[vocab.stoi[emb_word]] = torch.FloatTensor(embedding)
|
| 37 |
+
print("\nEmbeddings loaded!")
|
| 38 |
+
return embeddings, embed_dims
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def save_model(model, num_epochs, optimizer, train_loss, val_loss, vocab):
|
| 42 |
+
model_state = {
|
| 43 |
+
'num_epochs': num_epochs,
|
| 44 |
+
'vocab': vocab,
|
| 45 |
+
'vocab_size': len(vocab.stoi),
|
| 46 |
+
'state_dict': model.state_dict(),
|
| 47 |
+
'optimizer_denoise_state_dict': optimizer,
|
| 48 |
+
'training_loss': train_loss,
|
| 49 |
+
'val_loss': val_loss,
|
| 50 |
+
}
|
| 51 |
+
torch.save(model_state, 'attention_model_state.pth')
|