---
license: apache-2.0
pipeline_tag: image-text-to-text
library_name: transformers
---
# Vision-SR1: Self-Rewarding Vision-Language Model via Reasoning Decomposition
This repository hosts the **Vision-SR1** model, a self-rewarding Vision-Language Model (VLM) introduced in the paper [**Self-Rewarding Vision-Language Model via Reasoning Decomposition**](https://huggingface.co/papers/2508.19652).
[📖 Paper](https://huggingface.co/papers/2508.19652) | [💻 Code](https://github.com/zli12321/Vision-SR1)
## Abstract
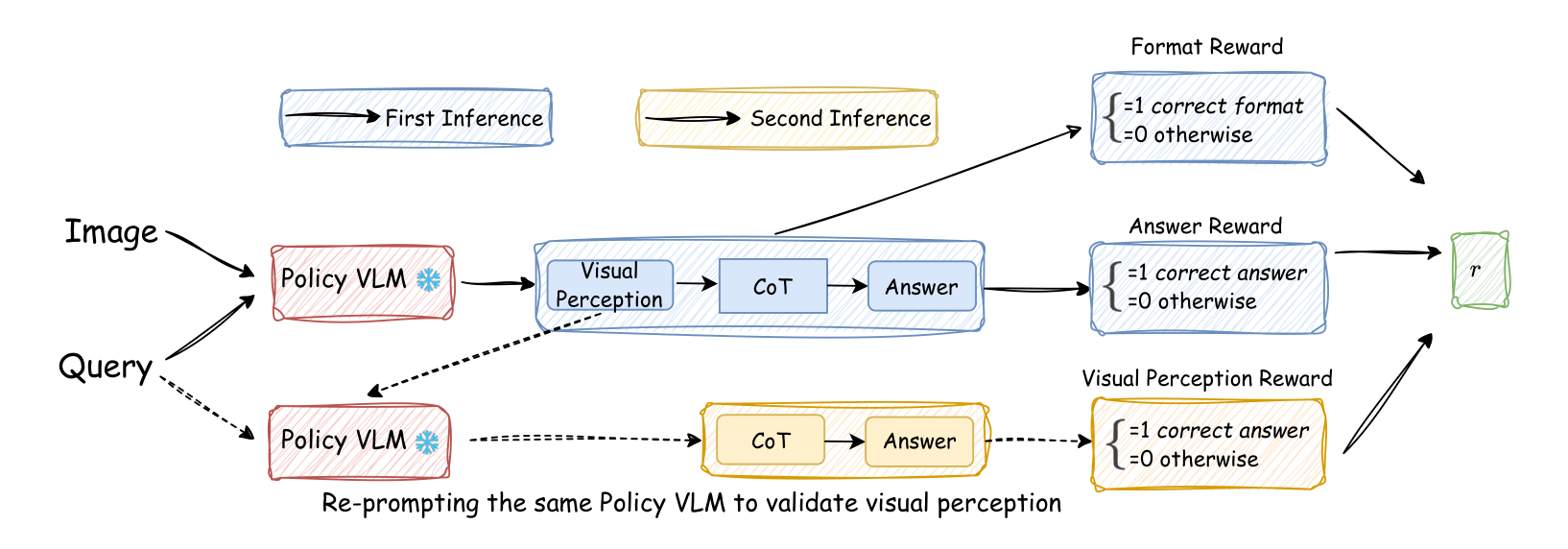
Vision-Language Models (VLMs) often suffer from visual hallucinations, saying things that are not actually in the image, and language shortcuts, where they skip the visual part and just rely on text priors. These issues arise because most post-training methods for VLMs rely on simple verifiable answer matching and supervise only final outputs, leaving intermediate visual reasoning without explicit guidance. As a result, VLMs receive sparse visual signals and often learn to prioritize language-based reasoning over visual perception. To mitigate this, some existing methods add visual supervision using human annotations or distilled labels from external large models. However, human annotations are labor-intensive and costly, and because external signals cannot adapt to the evolving policy, they cause distributional shifts that can lead to reward hacking. In this paper, we introduce Vision-SR1, a self-rewarding method that improves visual reasoning without relying on external visual supervisions via reinforcement learning. Vision-SR1 decomposes VLM reasoning into two stages: visual perception and language reasoning. The model is first prompted to produce self-contained visual perceptions that are sufficient to answer the question without referring back the input image. To validate this self-containment, the same VLM model is then re-prompted to perform language reasoning using only the generated perception as input to compute reward. This self-reward is combined with supervision on final outputs, providing a balanced training signal that strengthens both visual perception and language reasoning. Our experiments demonstrate that Vision-SR1 improves visual reasoning, mitigates visual hallucinations, and reduces reliance on language shortcuts across diverse vision-language tasks.
## 👀 About Vision-SR1
Vision-SR1 is a self-rewarded RL training framework to decompose VLMs' language reasoning into visual perception reasoning and language reasoning. Inspired by the awesome works of e.g. Vision-R1, Visionary-R1, R1-VL, we leverage VLM's self evolving and reasoning ability to **Reward Itself**.
Because VLMs fuse the vision encoder with the LLM backbone only late in pretraining, they often rely primarily on language reasoning rather than visual perception. Standard RL training tends to **recall prior language knowledge** for accuracy gains while **neglecting vision**. External LLM-based perception rewards can help but introduce bias and heavy latency. We instead propose a self-reward framework, enabling the model to provide its own visual and reasoning feedback with **no latency**.
Besides vision decomposition, We constructed two datasets: **Vsion-SR1-Cold-9K** for SFT and **Vision-SR1-47K** for RL.
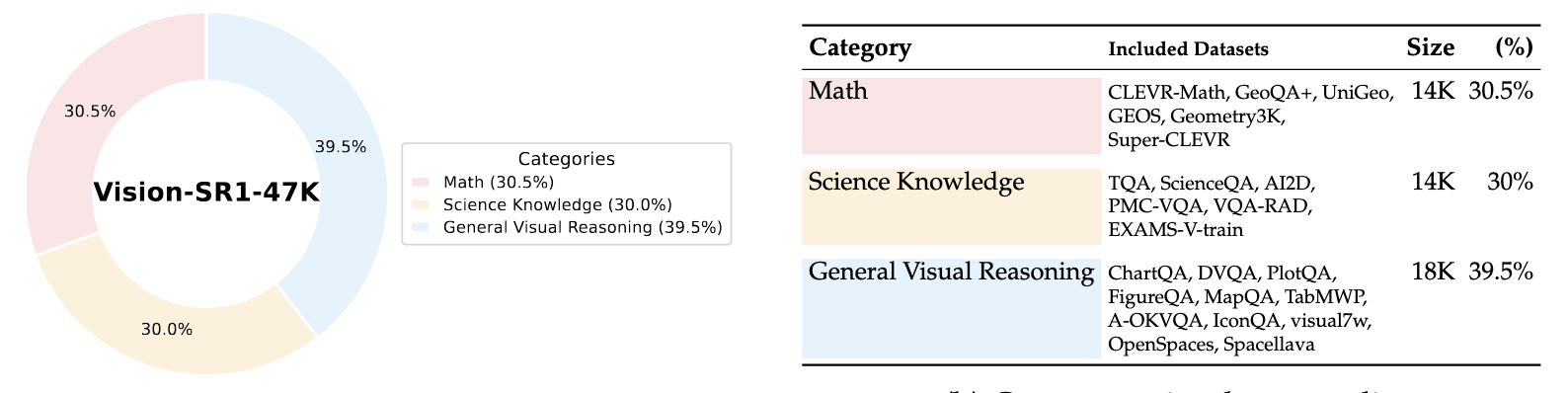
### 🔍 Dataset
Our training dataset is sourced from 23 sources and evenly split across three main areas-- general visual understanding, science knowledge, multimodal mathematical reasoning.
## Related Hugging Face Artifacts
**Models:**
* [🤗 Vision-SR1-7B](https://huggingface.co/LMMs-Lab-Turtle/SelfRewarded-R1-7B)
* [🤗 Vision-SR1-7B-Cold-Start](https://huggingface.co/LMMs-Lab-Turtle/Qwen-2.5VL-7B-Cold-Start)
* [🤗 Vision-SR1-3B-Cold-Start](https://huggingface.co/LMMs-Lab-Turtle/Qwen-2.5VL-3B-Cold-Start)
**Datasets:**
* [📊 Vision-SR1-Cold-Start-9K](https://huggingface.co/datasets/LMMs-Lab-Turtle/Vision-SR1-Cold-9K)
* [📊 Vision-SR1-47K](https://huggingface.co/datasets/LMMs-Lab-Turtle/Vision-SR1-47K)
## Citation
If you find our works helpful, please cite the source code work:
```bibtex
@misc{zheng2025easyr1,
title = {EasyR1: An Efficient, Scalable, Multi-Modality RL Training Framework},
author = {Yaowei Zheng, Junting Lu, Shenzhi Wang, Zhangchi Feng, Dongdong Kuang, Yuwen Xiong},
howpublished = {\url{https://github.com/hiyouga/EasyR1}},
year = {2025}
}
```